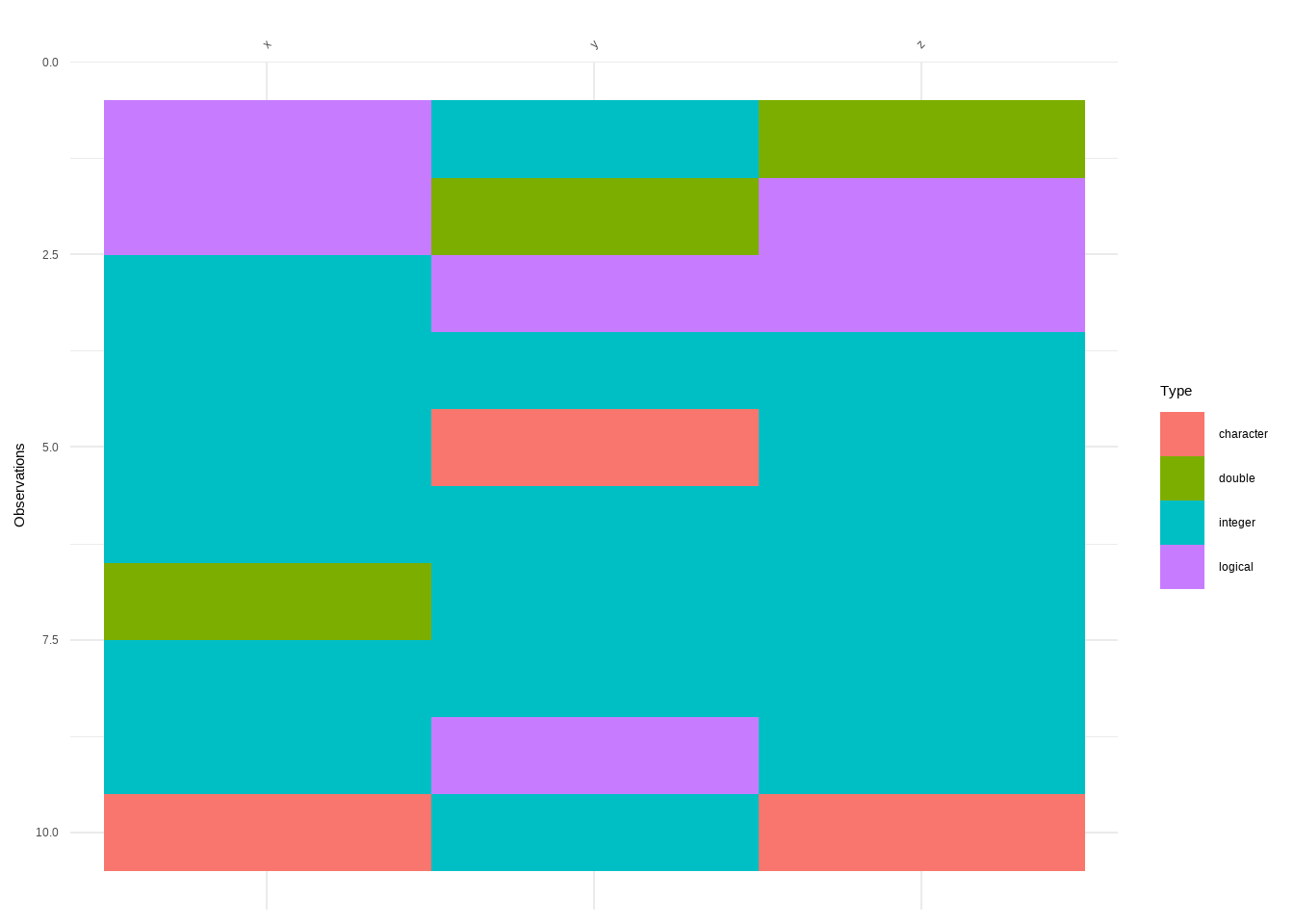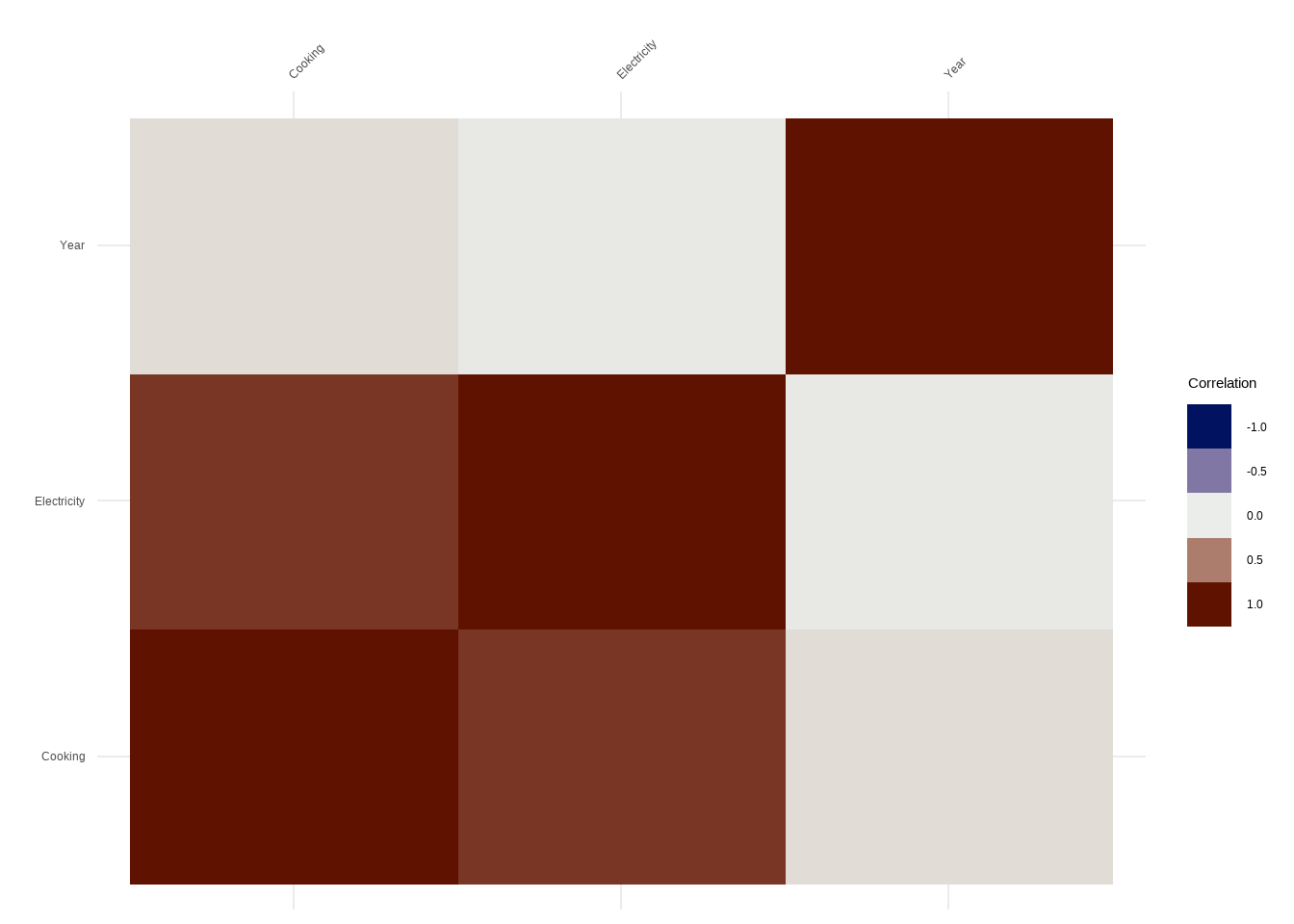Data quality analysis is the process of evaluating the quality of data against a set of defined standards or requirements. It ensures that the data is fit for its intended use by checking for errors, inconsistencies, and other issues.
Required software and packages
R Software
RStudio
Following packages:
tidyverse
rmarkdown
knitr
data.validator
dlookr
skimr
naniar
visdat
denguedatahub
DSjobtracker
Data sets
denguedatahub::srilanka_weekly_data
library (tibble)library (denguedatahub)data (srilanka_weekly_data)
# A tibble: 23,882 × 6
year week start.date end.date district cases
<dbl> <dbl> <date> <date> <chr> <dbl>
1 2006 52 2006-12-23 2006-12-29 Colombo 71
2 2006 52 2006-12-23 2006-12-29 Gampaha 12
3 2006 52 2006-12-23 2006-12-29 Kalutara 12
4 2006 52 2006-12-23 2006-12-29 Kandy 20
5 2006 52 2006-12-23 2006-12-29 Matale 4
6 2006 52 2006-12-23 2006-12-29 NuwaraEliya 1
7 2006 52 2006-12-23 2006-12-29 Galle 1
8 2006 52 2006-12-23 2006-12-29 Hambanthota 1
9 2006 52 2006-12-23 2006-12-29 Matara 11
10 2006 52 2006-12-23 2006-12-29 Jaffna 0
# ℹ 23,872 more rows
denguedatahub::world_annual
library (tibble)data (world_annual)as_tibble (world_annual)
# A tibble: 2,773,284 × 10
long lat group order region subregion code year incidence dengue.present
<dbl> <dbl> <dbl> <int> <chr> <chr> <chr> <dbl> <dbl> <chr>
1 -69.9 12.5 1 1 Aruba <NA> <NA> NA NA <NA>
2 -69.9 12.4 1 2 Aruba <NA> <NA> NA NA <NA>
3 -69.9 12.4 1 3 Aruba <NA> <NA> NA NA <NA>
4 -70.0 12.5 1 4 Aruba <NA> <NA> NA NA <NA>
5 -70.1 12.5 1 5 Aruba <NA> <NA> NA NA <NA>
6 -70.1 12.6 1 6 Aruba <NA> <NA> NA NA <NA>
7 -70.0 12.6 1 7 Aruba <NA> <NA> NA NA <NA>
8 -70.0 12.6 1 8 Aruba <NA> <NA> NA NA <NA>
9 -69.9 12.5 1 9 Aruba <NA> <NA> NA NA <NA>
10 -69.9 12.5 1 10 Aruba <NA> <NA> NA NA <NA>
# ℹ 2,773,274 more rows
Data Profiling
Data Profiling is about exploring the data. It helps us to identify the characteristics of a dataset, such as its dimensions, data types, and overall structure.
Data Description: denguedatahub::srilanka_weekly_data
Method 1
R Code:…………………………….
Data summary
Name
srilanka_weekly_data
Number of rows
23882
Number of columns
6
_______________________
Column type frequency:
character
1
Date
2
numeric
3
________________________
Group variables
None
Variable type: character
Variable type: Date
start.date
0
1
2006-12-23
2024-07-27
2015-10-10
919
end.date
0
1
2006-12-29
2024-08-02
2015-10-16
919
Variable type: numeric
year
0
1
2015.29
5.09
2006
2011
2015
2020
2024
▆▇▆▇▇
week
0
1
26.30
15.05
1
13
26
39
53
▇▇▇▇▇
cases
0
1
31.21
82.00
0
2
8
28
2631
▇▁▁▁▁
Method 2
R Code:…………………………….
variable q_zeros p_zeros q_na p_na q_inf p_inf type unique
year year 0 0.0000000 0 0 0 0 numeric 19
week week 0 0.0000000 0 0 0 0 numeric 53
start.date start.date 0 0.0000000 0 0 0 0 Date 919
end.date end.date 0 0.0000000 0 0 0 0 Date 919
district district 0 0.0000000 0 0 0 0 character 26
cases cases 3551 0.1486894 0 0 0 0 numeric 530
R Code:…………………………….
$vars_num_with_NA
[1] variable q_na p_na
<0 rows> (or 0-length row.names)
$vars_cat_with_NA
[1] variable q_na p_na
<0 rows> (or 0-length row.names)
$vars_cat_high_card
[1] variable unique
<0 rows> (or 0-length row.names)
$MAX_UNIQUE
[1] 35
$vars_one_value
character(0)
$vars_cat
[1] "district"
$vars_num
[1] "year" "week" "cases"
$vars_char
[1] "district"
$vars_factor
character(0)
$vars_other
[1] "start.date" "end.date"
R Code:…………………………….
variable mean std_dev variation_coef p_01 p_05 p_25 p_50 p_75 p_95
1 year 2015.29051 5.086737 0.002524072 2007 2007 2011 2015 2020 2023.00
2 week 26.30437 15.053717 0.572289560 1 3 13 26 39 50.00
3 cases 31.21108 81.997804 2.627201806 0 0 2 8 28 128.95
p_99 skewness kurtosis iqr range_98 range_80
1 2024.00 0.006609632 1.803220 9 [2007, 2024] [2008, 2022]
2 52.00 0.032334528 1.809499 26 [1, 52] [6, 47]
3 358.38 10.286018979 192.982559 26 [0, 358.379999999997] [0, 73]
Distribution of Numeric Variables
R Code:…………………………….
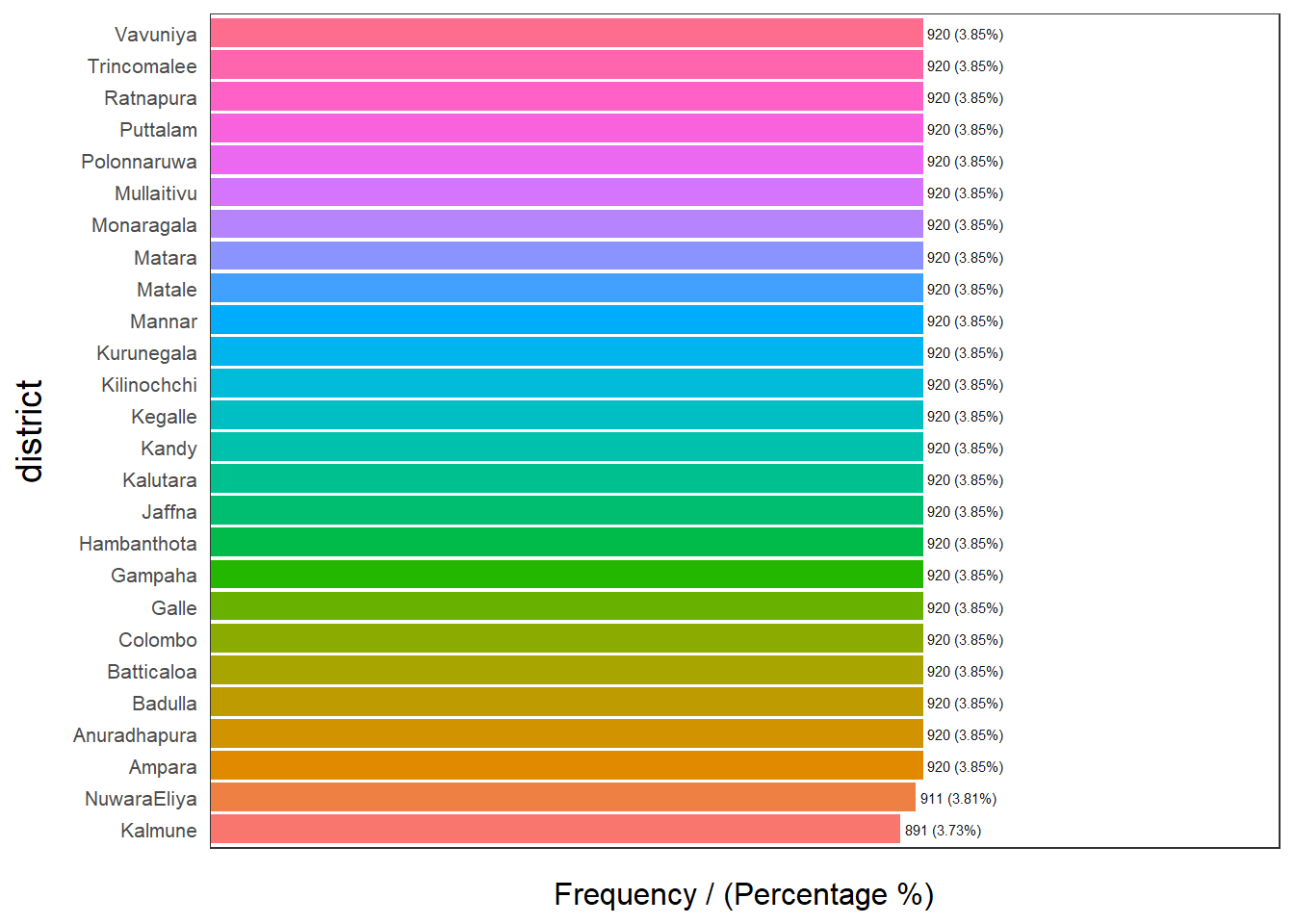
Distribution of Categorical Variables
R Code:…………………………….
district frequency percentage cumulative_perc
1 Ampara 920 3.85 3.85
2 Anuradhapura 920 3.85 7.70
3 Badulla 920 3.85 11.55
4 Batticaloa 920 3.85 15.40
5 Colombo 920 3.85 19.25
6 Galle 920 3.85 23.10
7 Gampaha 920 3.85 26.95
8 Hambanthota 920 3.85 30.80
9 Jaffna 920 3.85 34.65
10 Kalutara 920 3.85 38.50
11 Kandy 920 3.85 42.35
12 Kegalle 920 3.85 46.20
13 Kilinochchi 920 3.85 50.05
14 Kurunegala 920 3.85 53.90
15 Mannar 920 3.85 57.75
16 Matale 920 3.85 61.60
17 Matara 920 3.85 65.45
18 Monaragala 920 3.85 69.30
19 Mullaitivu 920 3.85 73.15
20 Polonnaruwa 920 3.85 77.00
21 Puttalam 920 3.85 80.85
22 Ratnapura 920 3.85 84.70
23 Trincomalee 920 3.85 88.55
24 Vavuniya 920 3.85 92.40
25 NuwaraEliya 911 3.81 96.21
26 Kalmune 891 3.73 100.00
Method 3
R Code:…………………………….
# A tibble: 3 × 6
variables types missing_count missing_percent unique_count unique_rate
<chr> <chr> <int> <dbl> <int> <dbl>
1 year integer 0 0 1 0.000333
2 month integer 0 0 12 0.004
3 day integer 0 0 31 0.0103
Data Description: denguedatahub::world_annual
R Code:…………………………….
Data summary
Name
world_annual
Number of rows
2773284
Number of columns
10
_______________________
Column type frequency:
character
4
numeric
6
________________________
Group variables
None
Variable type: character
region
0
1.00
2
35
0
282
0
subregion
1783783
0.36
1
33
0
1069
0
code
7854
1.00
3
8
0
202
0
dengue.present
7164
1.00
2
3
0
2
0
Variable type: numeric
long
900
1
12.64
85.44
-180.00
-67.60
19.10
80.68
190.27
▂▆▇▆▃
lat
900
1
30.24
32.65
-85.19
6.95
36.81
55.33
83.60
▁▂▆▇▇
group
900
1
834.10
457.79
1.00
417.00
847.00
1296.00
1627.00
▅▇▆▅▇
order
900
1
52582.05
28142.60
1.00
28173.00
52658.00
77045.00
100964.00
▆▇▇▇▇
year
7164
1
2004.50
8.66
1990.00
1997.00
2004.50
2012.00
2019.00
▇▇▇▇▇
incidence
7164
1
701055.46
3036888.47
0.00
0.00
0.00
99597.00
56878730.00
▇▁▁▁▁
Method 2:
variable q_zeros p_zeros q_na p_na q_inf
long long 721 0.0002599806 900 0.000324525 0
lat lat 0 0.0000000000 900 0.000324525 0
group group 0 0.0000000000 900 0.000324525 0
order order 0 0.0000000000 900 0.000324525 0
region region 0 0.0000000000 0 0.000000000 0
subregion subregion 0 0.0000000000 1783783 0.643202427 0
code code 0 0.0000000000 7854 0.002832022 0
year year 0 0.0000000000 7164 0.002583219 0
incidence incidence 1423590 0.5133228331 7164 0.002583219 0
dengue.present dengue.present 0 0.0000000000 7164 0.002583219 0
p_inf type unique
long 0 numeric 76880
lat 0 numeric 76361
group 0 numeric 1627
order 0 integer 99338
region 0 character 282
subregion 0 character 1069
code 0 character 202
year 0 numeric 30
incidence 0 numeric 4109
dengue.present 0 character 2
data_integrity (world_annual)
$vars_num_with_NA
variable q_na p_na
long long 900 0.000324525
lat lat 900 0.000324525
group group 900 0.000324525
order order 900 0.000324525
year year 7164 0.002583219
incidence incidence 7164 0.002583219
$vars_cat_with_NA
variable q_na p_na
subregion subregion 1783783 0.643202427
code code 7854 0.002832022
dengue.present dengue.present 7164 0.002583219
$vars_cat_high_card
variable unique
subregion subregion 1069
region region 282
code code 202
$MAX_UNIQUE
[1] 35
$vars_one_value
character(0)
$vars_cat
[1] "region" "subregion" "code" "dengue.present"
$vars_num
[1] "long" "lat" "group" "order" "year" "incidence"
$vars_char
[1] "region" "subregion" "code" "dengue.present"
$vars_factor
character(0)
$vars_other
character(0)
profiling_num (world_annual)
variable mean std_dev variation_coef p_01 p_05
1 long 12.63966 8.543838e+01 6.759545411 -164.0733 -125.18413
2 lat 30.24176 3.265450e+01 1.079781713 -51.7249 -29.59932
3 group 834.10077 4.577919e+02 0.548844831 10.0000 184.00000
4 order 52582.04712 2.814260e+04 0.535213158 949.0000 9447.00000
5 year 2004.50000 8.655443e+00 0.004318006 1990.0000 1991.00000
6 incidence 701055.45849 3.036888e+06 4.331880495 0.0000 0.00000
p_25 p_50 p_75 p_95 p_99 skewness
1 -67.596336 19.09844 80.68213 1.445178e+02 1.746725e+02 -0.07340286
2 6.946973 36.81196 55.33027 7.582597e+01 8.078438e+01 -0.51056358
3 417.000000 847.00000 1296.00000 1.569000e+03 1.621000e+03 0.06183424
4 28173.000000 52658.00000 77045.00000 9.621100e+04 1.000290e+05 -0.02092148
5 1997.000000 2004.50000 2012.00000 2.018000e+03 2.019000e+03 0.00000000
6 0.000000 0.00000 99597.00000 2.616088e+06 2.137839e+07 7.04612715
kurtosis iqr range_98
1 2.091961 148.2785 [-164.073287963867, 174.672546386719]
2 2.553684 48.3833 [-51.7249031066895, 80.7843780517578]
3 1.727049 879.0000 [10, 1621]
4 1.826357 48872.0000 [949, 100029]
5 1.797330 15.0000 [1990, 2019]
6 55.475409 99597.0000 [0, 21378391]
range_80
1 [-95.987060546875, 126.757331848145]
2 [-14.16845703125, 70.2992172241211]
3 [242, 1441]
4 [14136, 91463]
5 [1992.90000000002, 2016.10000000009]
6 [0, 1723528]
Distribution of Numeric Variables
Distribution of Categorical Variables
Note: Output has been omitted due to its length.
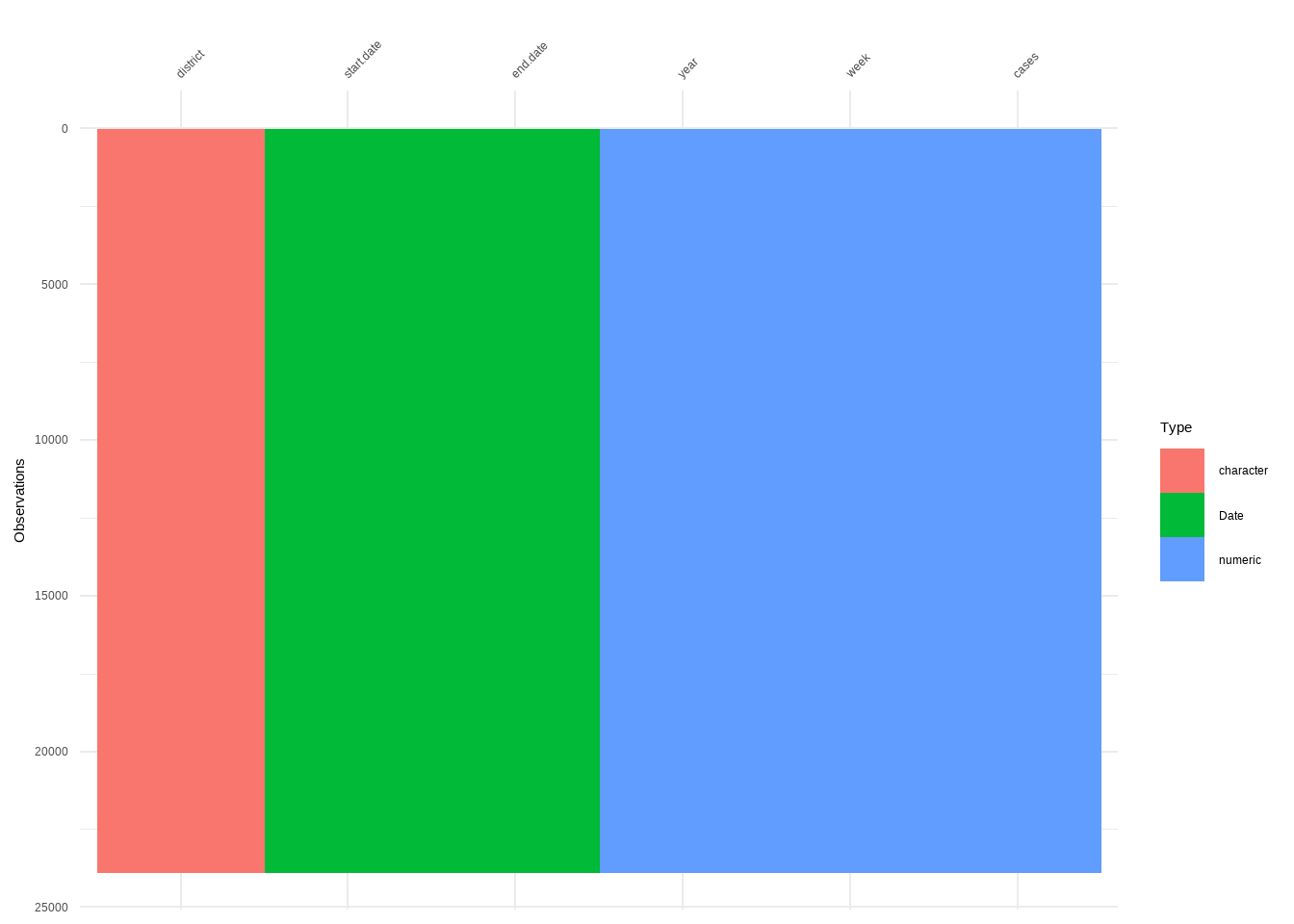
Variable Types
denguedatahub::srilanka_weekly_data
R Code:…………………………….
Question: Why is there no observable variability in the cases column?
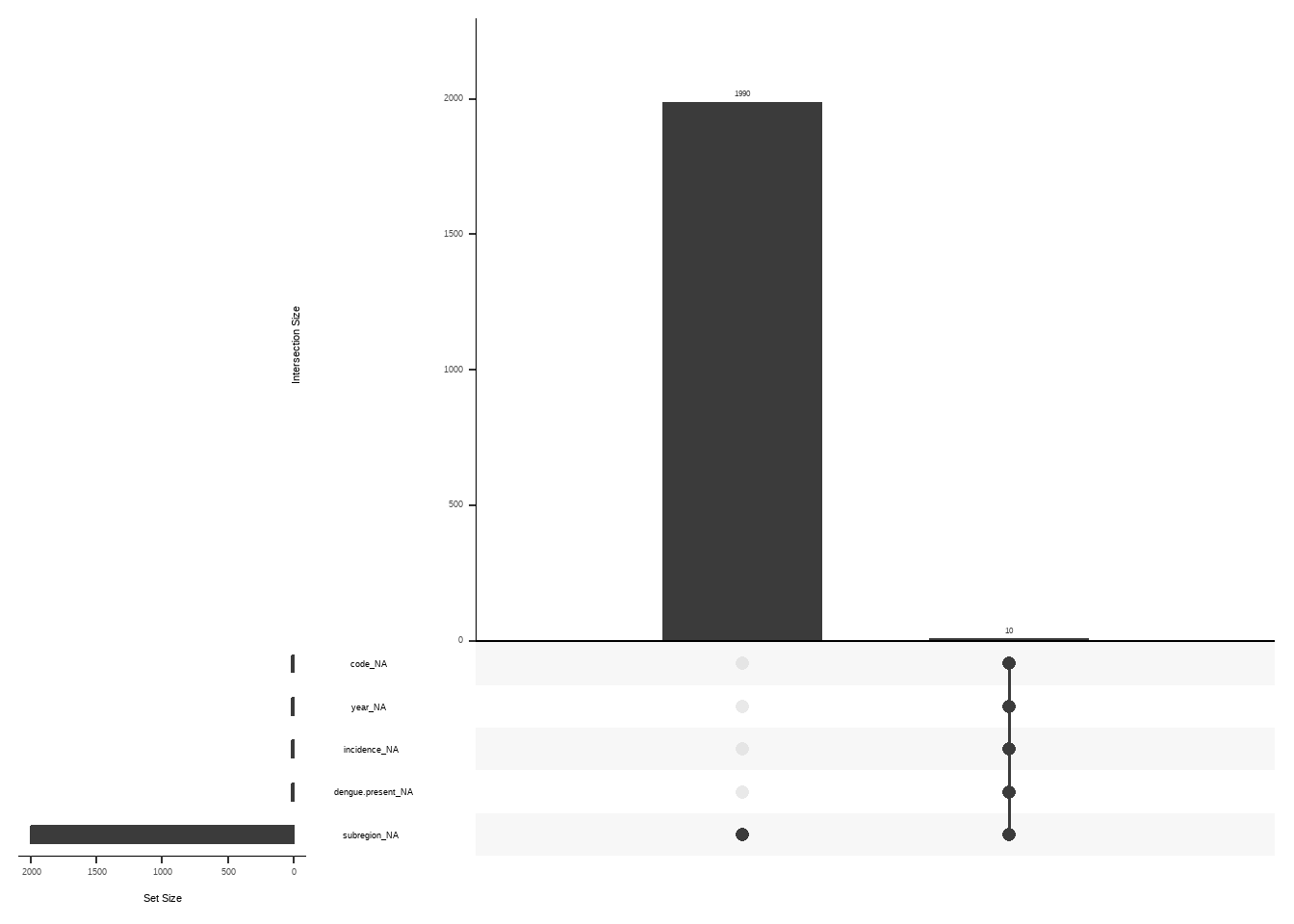
denguedatahub::world_annual
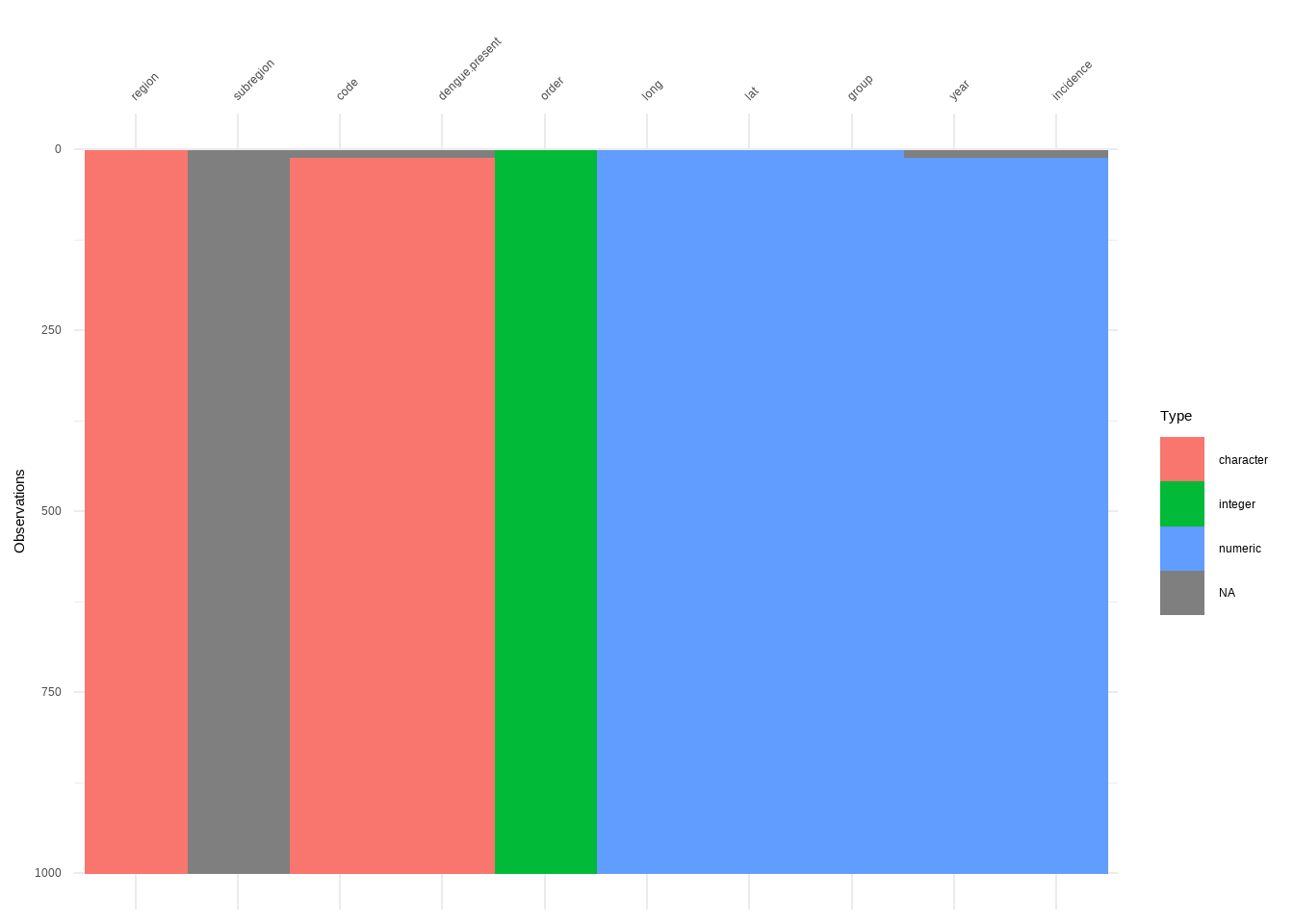
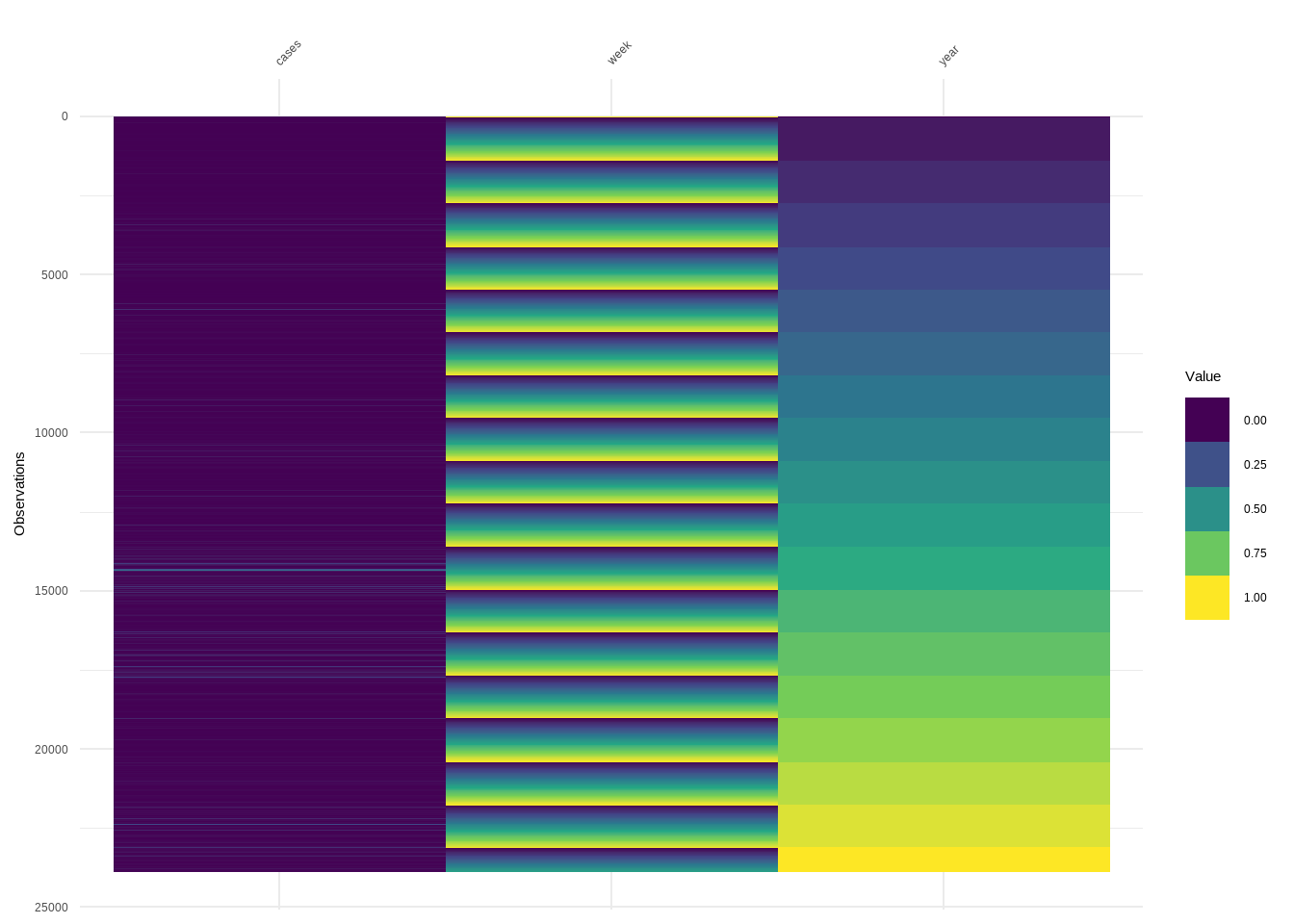
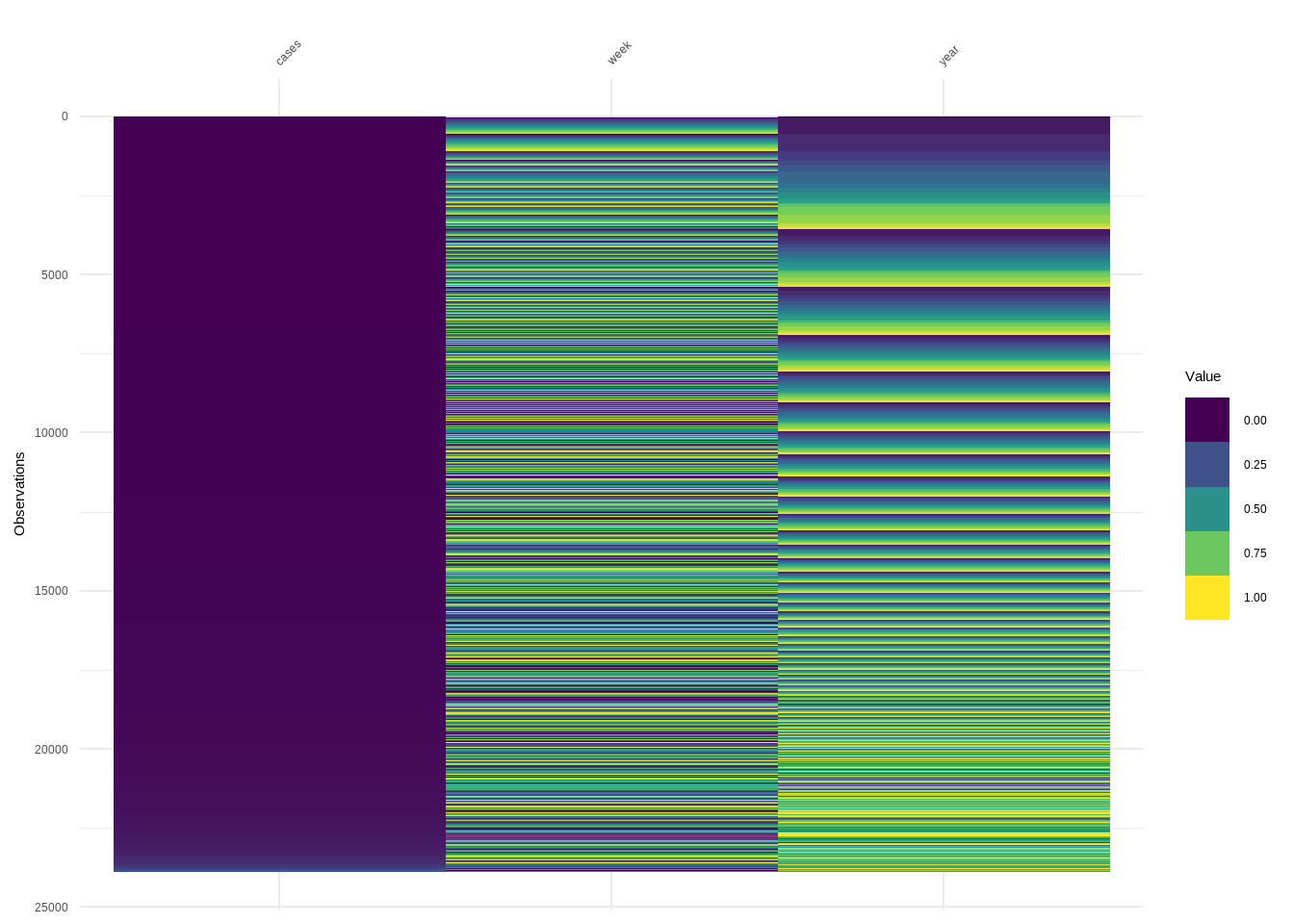
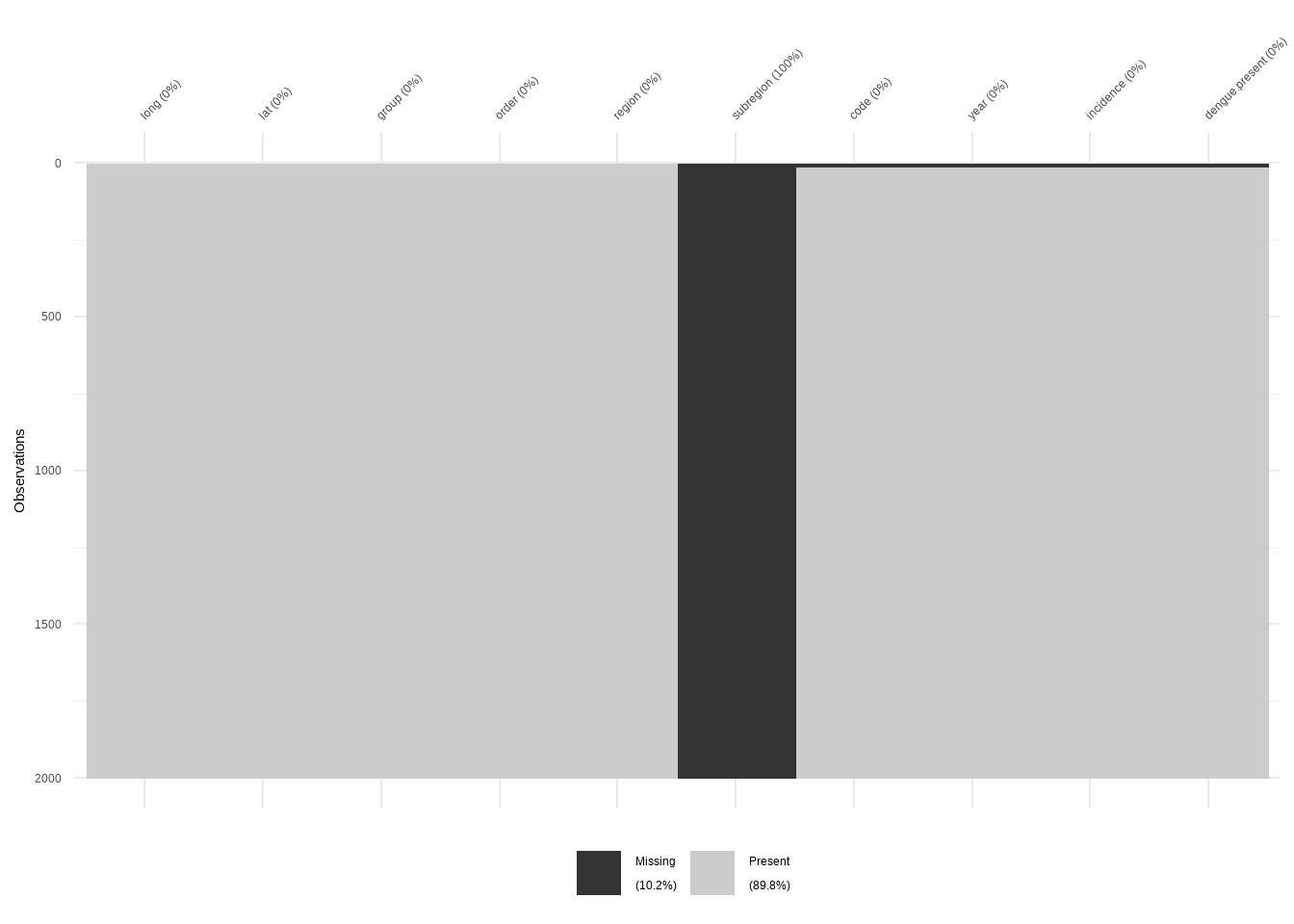
This example shows how to work with a large dataset with visdat
R Code:…………………………….
Visualising Numerial Data
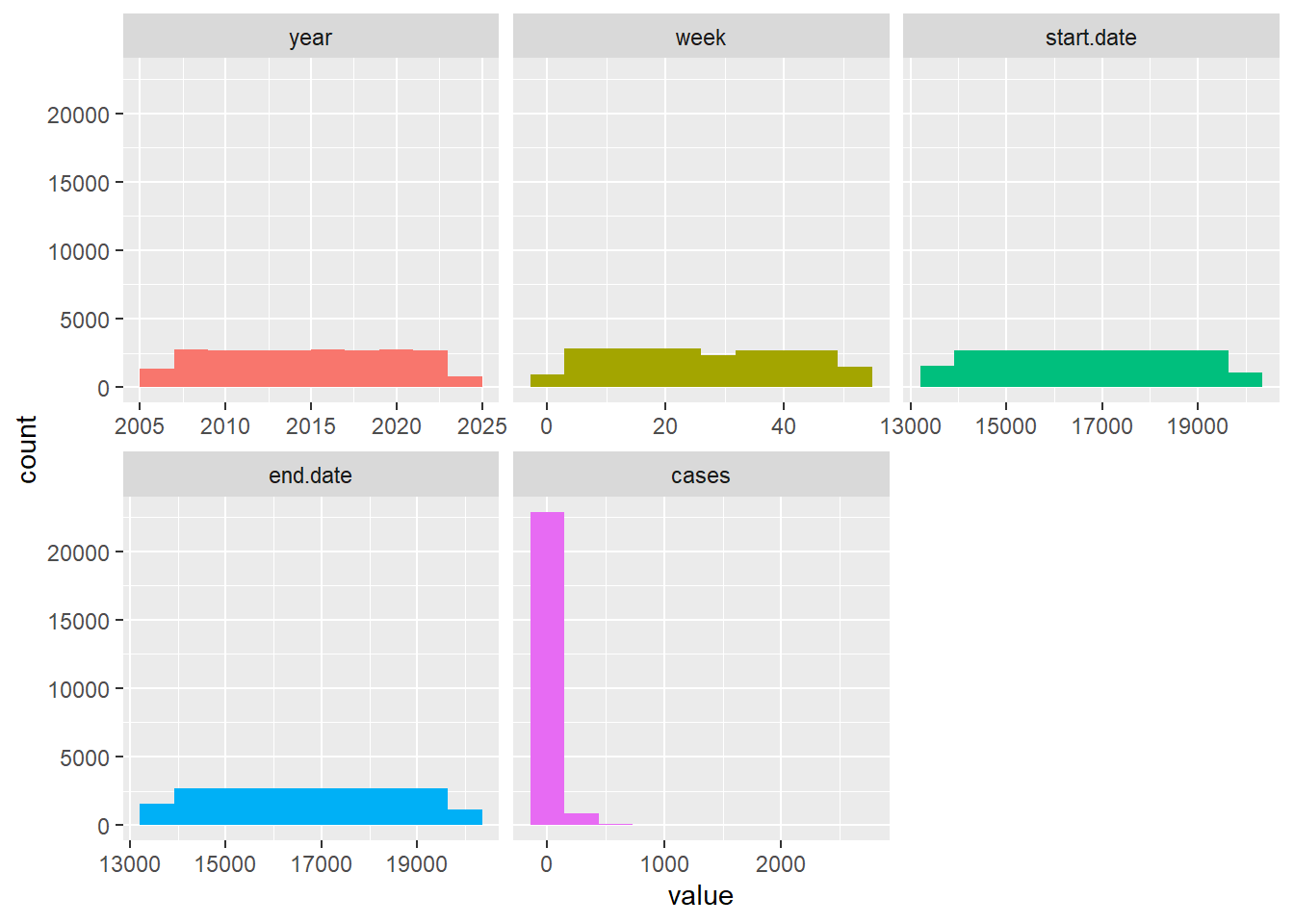
denguedatahub::srilanka_weekly_data
R Code:…………………………….
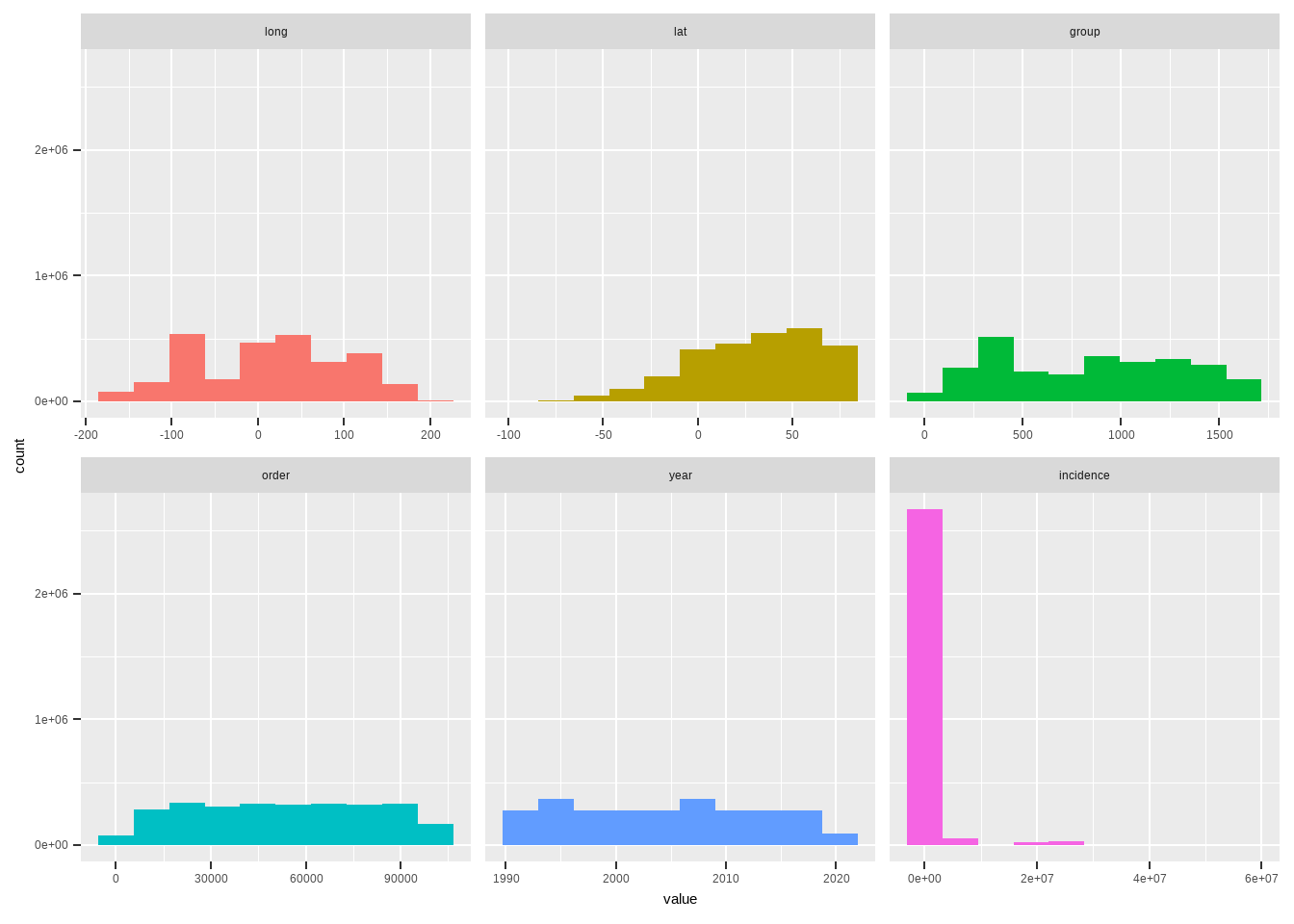
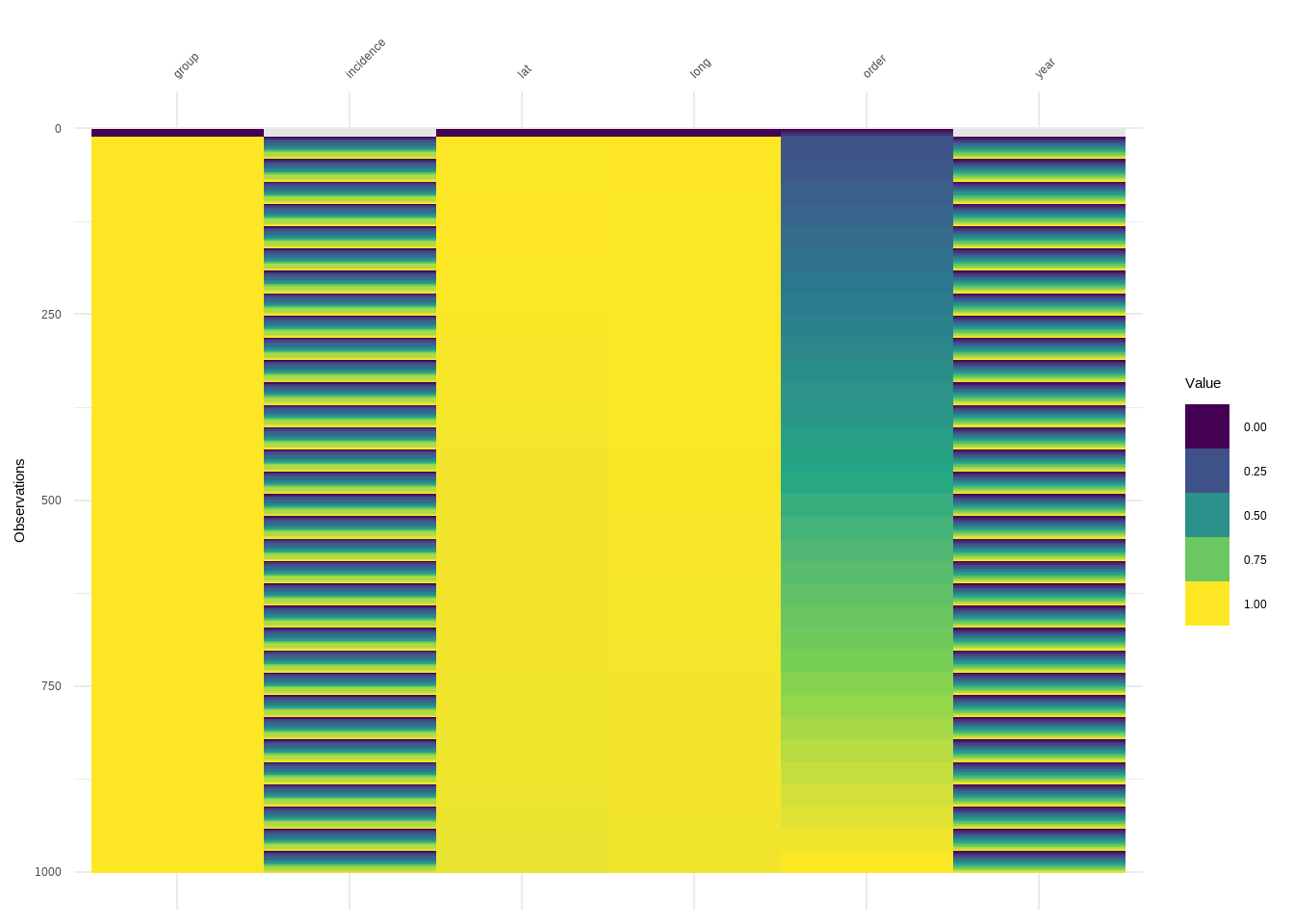
denguedatahub::world_annual
R Code:…………………………….
Arrange Data Before Plotting Numeric Variables
denguedatahub::srilanka_weekly_data
R Code:…………………………….
Visualise Binary Variables in the Data
## Sample dataset <- tibble (x= rep (c (1 , 0 ), 50 ), y= c (rep (1 , 50 ), rep (0 , 50 )))
R Code:…………………………….
Visualise Messy Data Sets with Mixed Data Types
R Code:…………………………….
# A tibble: 10 × 3
x y z
<chr> <chr> <chr>
1 TRUE 200 30.5
2 TRUE 30.5 TRUE
3 1 TRUE TRUE
4 200 0 1
5 1 2014/1/2 1
6 30 1 0
7 30.5 1 1
8 1 1 30
9 0 TRUE 200
10 2014/1/2 30 2014/1/2
Visualise the Data Set
R Code:…………………………….
Cell Identification Challenge: Guess the Function of Each Cell
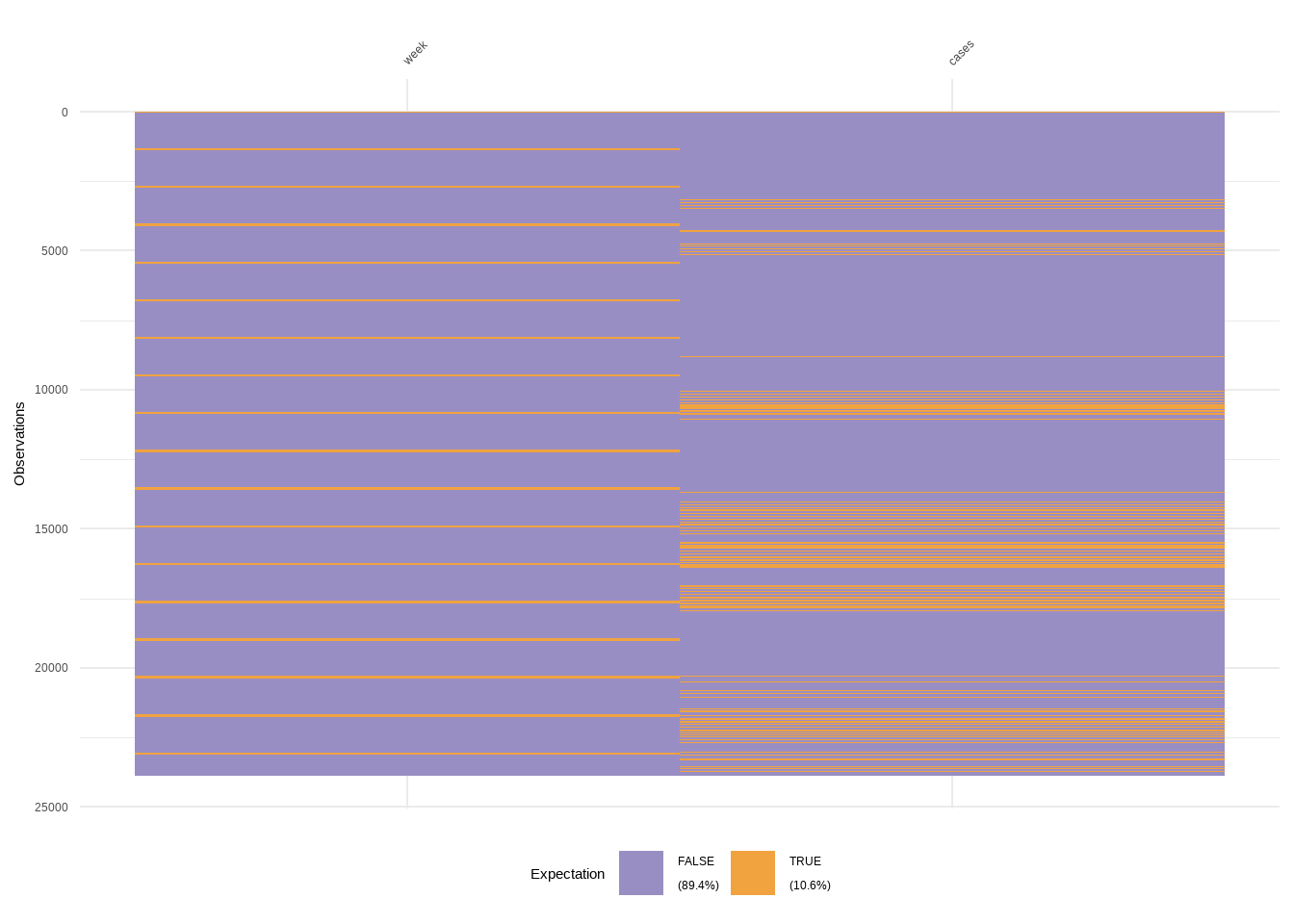
Data Completeness
Visualize the distribution of missing data.
denguedatahub::srilanka_weekly_data
R Code:…………………………….
denguedatahub::world_annual
R Code:…………………………….
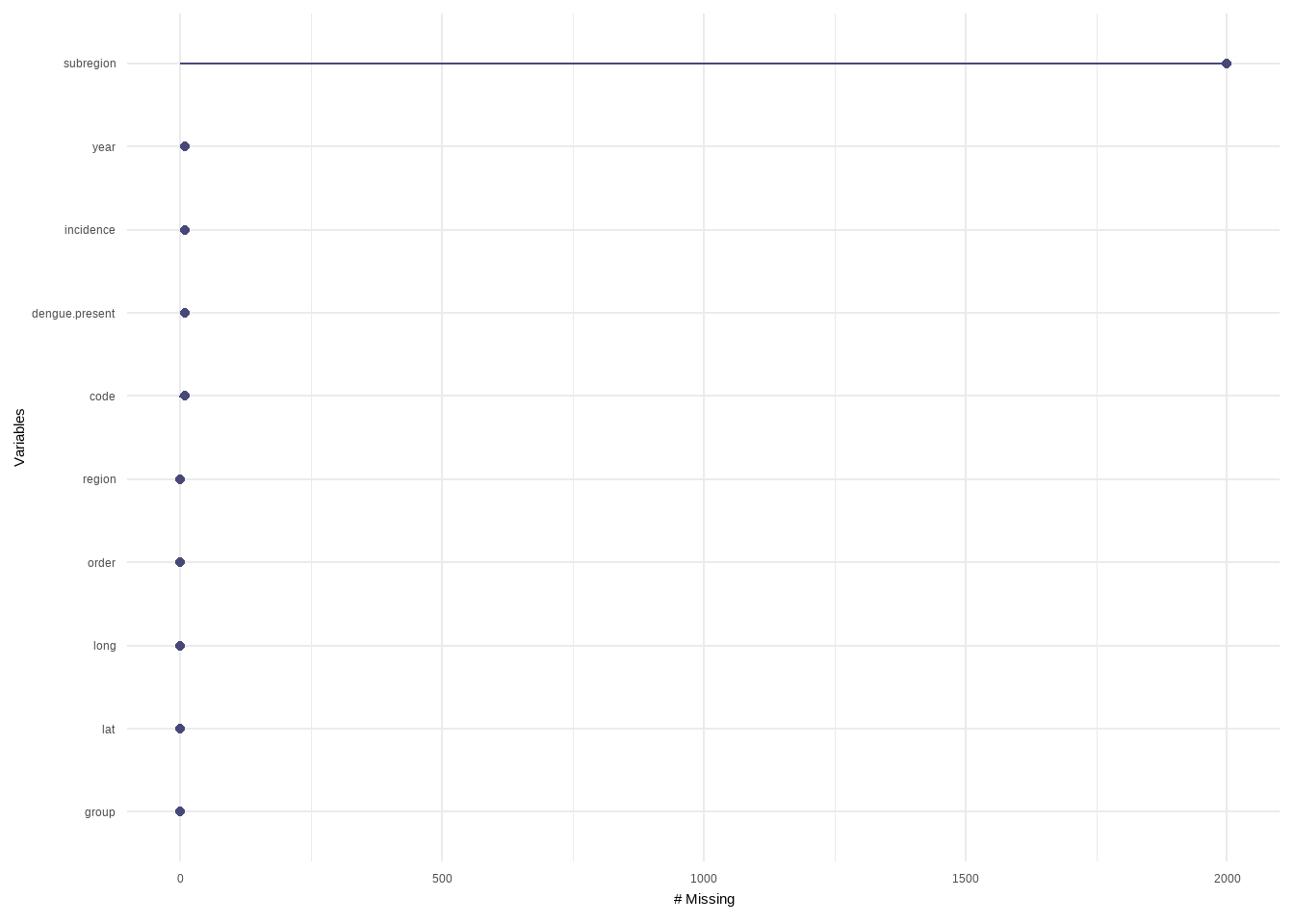
Visualise Missing in Variables
R Code:…………………………….
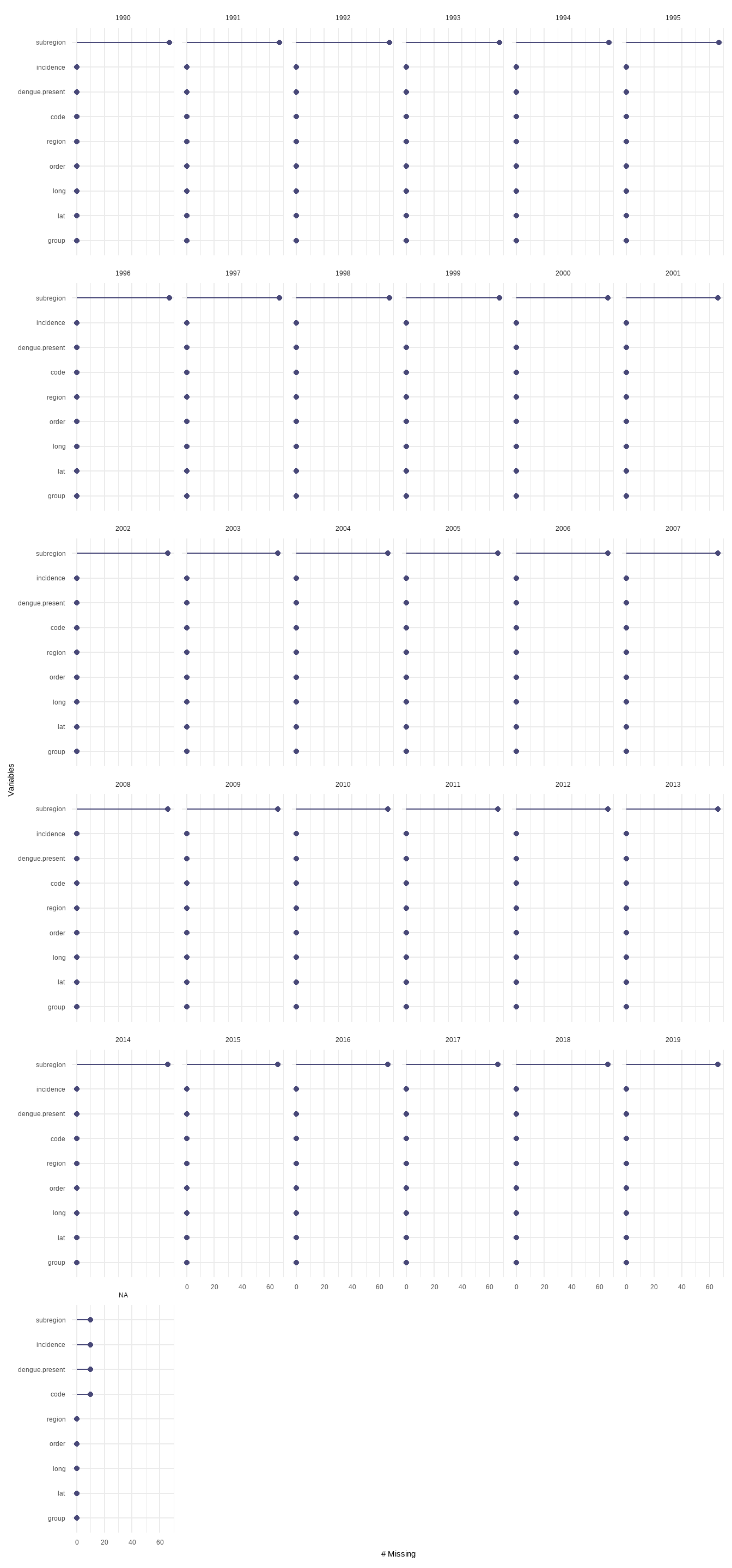
Small multiples of the same plot facet by year
R Code:…………………………….
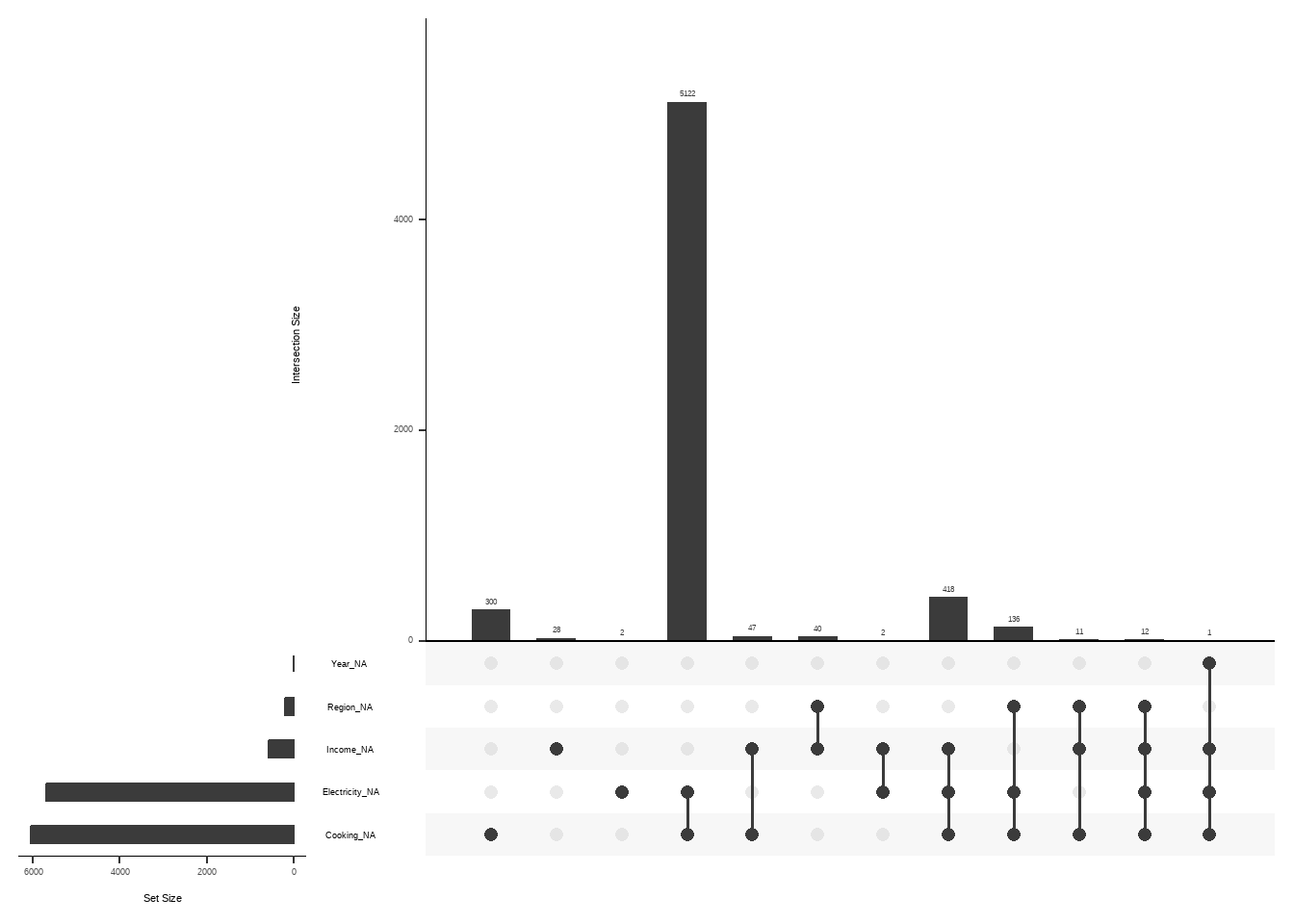
Explore Missing Relationships
denguedatahub::srilanka_weekly_data
R Code:…………………………….
drone::worldbankdata
# install.packages("devtools") :: install_github ("thiyangt/drone" )
library (tibble)library (drone)data ("worldbankdata" )
# A tibble: 7,937 × 7
Country Code Region Year Cooking Electricity Income
<fct> <fct> <fct> <dbl> <dbl> <dbl> <fct>
1 Aruba ABW Latin America & Caribbean 1990 NA 100 H
2 Aruba ABW Latin America & Caribbean 2000 NA 91.7 H
3 Aruba ABW Latin America & Caribbean 2013 NA 100 H
4 Aruba ABW Latin America & Caribbean 2014 NA 100 H
5 Aruba ABW Latin America & Caribbean 2015 NA 100 H
6 Aruba ABW Latin America & Caribbean 2016 NA 100 H
7 Aruba ABW Latin America & Caribbean 2017 NA 100 H
8 Aruba ABW Latin America & Caribbean 2018 NA 100 H
9 Aruba ABW Latin America & Caribbean 2019 NA 100 H
10 Aruba ABW Latin America & Caribbean 2020 NA 100 H
# ℹ 7,927 more rows
Your turn: Perform a data profiling analysis on worldbankdata.
|> as_shadow_upset () |> :: upset ()
Visualizing Values That Meet Specific Conditions
Visualize values greater than 50 in the cases Column of the srilanka_weekly_data dataset.
R Code:…………………………….
Descriptive Statistcs
denguedatahub::srilanka_weekly_data
R Code:…………………………….
describe (srilanka_weekly_data)
# A tibble: 3 × 26
described_variables n na mean sd se_mean IQR skewness kurtosis
<chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 year 23882 0 2015. 5.09 0.0329 9 0.00661 -1.20
2 week 23882 0 26.3 15.1 0.0974 26 0.0323 -1.19
3 cases 23882 0 31.2 82.0 0.531 26 10.3 190.
# ℹ 17 more variables: p00 <dbl>, p01 <dbl>, p05 <dbl>, p10 <dbl>, p20 <dbl>,
# p25 <dbl>, p30 <dbl>, p40 <dbl>, p50 <dbl>, p60 <dbl>, p70 <dbl>,
# p75 <dbl>, p80 <dbl>, p90 <dbl>, p95 <dbl>, p99 <dbl>, p100 <dbl>
denguedatahub::worldbankdata
R Code:…………………………….
# A tibble: 3 × 26
described_variables n na mean sd se_mean IQR skewness kurtosis
<chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Year 7936 1 2005. 10.4 0.117 18 -0.0123 -1.21
2 Cooking 1890 6047 65.5 38.5 0.885 72.7 -0.612 -1.31
3 Electricity 2244 5693 84.4 26.5 0.558 20.1 -1.63 1.32
# ℹ 17 more variables: p00 <dbl>, p01 <dbl>, p05 <dbl>, p10 <dbl>, p20 <dbl>,
# p25 <dbl>, p30 <dbl>, p40 <dbl>, p50 <dbl>, p60 <dbl>, p70 <dbl>,
# p75 <dbl>, p80 <dbl>, p90 <dbl>, p95 <dbl>, p99 <dbl>, p100 <dbl>
Diagnosing outliers
denguedatahub::srilanka_weekly_data
R Code:…………………………….
# A tibble: 3 × 6
variables outliers_cnt outliers_ratio outliers_mean with_mean without_mean
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 year 0 0 NaN 2015. 2015.
2 week 0 0 NaN 26.3 26.3
3 cases 2617 11.0 181. 31.2 12.8
denguedatahub::worldbankdata
R Code:…………………………….
# A tibble: 3 × 6
variables outliers_cnt outliers_ratio outliers_mean with_mean without_mean
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 Year 0 0 NaN 2005. 2005.
2 Cooking 0 0 NaN 65.5 65.5
3 Electricity 330 4.16 28.1 84.4 94.1
Bi-variate relationships
drone::worldbankdata
R Code:…………………………….
Exercise
Explore the methodologies behind each code used to generate the outputs.
Explore data validation methods implemented in R.
Perform data quality analysis for the following datasets and properly report your findings:
Datasets in the denguedatahub package in R
Datasets in the drone package in R
The penguins dataset in the palmerpenguins package in R
Perform a data quality analysis on the following data set.
library (DSjobtracker)data (DSraw)